Exception in thread "main" java.lang.IllegalArgumentException: Can't get Kerberos realm at org.apache.hadoop.security.HadoopKerberosName.setConfiguration(HadoopKerberosName.java:65) at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:249) at org.apache.hadoop.security.UserGroupInformation.setConfiguration(UserGroupInformation.java:285) at HdfsConnKerberos.HDFSClient.main(HDFSClient.java:43) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144) Caused by: java.lang.reflect.InvocationTargetException at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) at org.apache.hadoop.security.authentication.util.KerberosUtil.getDefaultRealm(KerberosUtil.java:84) at org.apache.hadoop.security.HadoopKerberosName.setConfiguration(HadoopKerberosName.java:63) ... 8 more Caused by: KrbException: Cannot locate default realm at sun.security.krb5.Config.getDefaultRealm(Config.java:1006) ... 14 more Caused by: KrbException: Generic error (description in e-text) (60) - Unable to locate Kerberos realm at sun.security.krb5.Config.getRealmFromDNS(Config.java:1102) at sun.security.krb5.Config.getDefaultRealm(Config.java:987) ... 14 more
Call exception, tries=10, retries=31, started=48283 ms ago, cancelled=false, msg=com.google.protobuf.ServiceException: org.apache.hadoop.hbase.exceptions.ConnectionClosingException: Call to m1.node.hadoop/192.168.10.1:16000 failed on local exception: org.apache.hadoop.hbase.exceptions.ConnectionClosingException: Connection to m1.node.hadoop/192.168.10.1:16000 is closing. Call id=10, waitTime=1
1 2 3 4 5 6 7 8
2017-10-13 15:26:02,021 INFO [main] zookeeper.ZooKeeper (ZooKeeper.java:<init>(438)) - Initiating client connection, connectString=m1.node.hadoop:2181,m2.node.hadoop:2181,m3.node.hadoop:2181 sessionTimeout=180000 watcher=org.apache.hadoop.hbase.zookeeper.PendingWatcher@65b3f4a4 2017-10-13 15:26:02,077 INFO [main-SendThread(m3.node.hadoop:2181)] zookeeper.ClientCnxn (ClientCnxn.java:logStartConnect(1019)) - Opening socket connection to server m3.node.hadoop/192.168.10.3:2181. Will not attempt to authenticate using SASL (unknown error) 2017-10-13 15:26:02,079 INFO [main-SendThread(m3.node.hadoop:2181)] zookeeper.ClientCnxn (ClientCnxn.java:primeConnection(864)) - Socket connection established, initiating session, client: /192.168.2.199:59415, server: m3.node.hadoop/192.168.10.3:2181 2017-10-13 15:26:02,104 INFO [main-SendThread(m3.node.hadoop:2181)] zookeeper.ClientCnxn (ClientCnxn.java:onConnected(1279)) - Session establishment complete on server m3.node.hadoop/192.168.10.3:2181, sessionid = 0x35efece455700dd, negotiated timeout = 40000 2017-10-13 15:26:05,349 WARN [main] (NetworkAddressUtils.java:getLocalIpAddress(389)) - Your hostname, DESKTOP-5KM5T43 resolves to a loopback/non-reachable address: fe80:0:0:0:3433:e0f1:9aa7:18da%net4, but we couldn't find any external IP address! 2017-10-13 15:26:06,524 WARN [main] shortcircuit.DomainSocketFactory (DomainSocketFactory.java:<init>(117)) - The short-circuit local reads feature cannot be used because UNIX Domain sockets are not available on Windows. 2017-10-13 15:26:54,855 INFO [main] client.RpcRetryingCaller (RpcRetryingCaller.java:callWithRetries(146)) - Call exception, tries=10, retries=31, started=48283 ms ago, cancelled=false, msg=com.google.protobuf.ServiceException: org.apache.hadoop.hbase.exceptions.ConnectionClosingException: Call to m1.node.hadoop/192.168.10.1:16000 failed on local exception: org.apache.hadoop.hbase.exceptions.ConnectionClosingException: Connection to m1.node.hadoop/192.168.10.1:16000 is closing. Call id=10, waitTime=1 2017-10-13 15:27:15,012 INFO [main] client.RpcRetryingCaller (RpcRetryingCaller.java:callWithRetries(146)) - Call exception, tries=11, retries=31, started=68440 ms ago, cancelled=false, msg=com.google.protobuf.ServiceException: org.apache.hadoop.hbase.exceptions.ConnectionClosingException: Call to m1.node.hadoop/192.168.10.1:16000 failed on local exception: org.apache.hadoop.hbase.exceptions.ConnectionClosingException: Connection to m1.node.hadoop/192.168.10.1:16000 is closing. Call id=11, waitTime=1
2017-11-21 17:45:11,982 INFO [org.apache.zookeeper.ZooKeeper] - Initiating client connection, connectString=m1.node.hadoop:2181,m2.node.hadoop:2181,m3.node.hadoop:2181 sessionTimeout=90000 watcher=hconnection-0x66d189790x0, quorum=m1.node.hadoop:2181,m2.node.hadoop:2181,m3.node.hadoop:2181, baseZNode=/hbase-secure 2017-11-21 17:45:12,049 INFO [org.apache.zookeeper.ClientCnxn] - Opening socket connection to server m2.node.hadoop/192.168.10.2:2181. Will not attempt to authenticate using SASL (unknown error) 2017-11-21 17:45:12,050 INFO [org.apache.zookeeper.ClientCnxn] - Socket connection established to m2.node.hadoop/192.168.10.2:2181, initiating session 2017-11-21 17:45:12,065 INFO [org.apache.zookeeper.ClientCnxn] - Session establishment complete on server m2.node.hadoop/192.168.10.2:2181, sessionid = 0x25fdc95c59d001d, negotiated timeout = 40000 2017-11-21 17:45:15,386 WARN [] - Your hostname, DESKTOP-5KM5T43 resolves to a loopback/non-reachable address: fe80:0:0:0:3c56:c61d:8b18:745%net4, but we couldn't find any external IP address! ---------------获取集群信息----------------- 2017-11-21 17:45:54,986 INFO [org.apache.hadoop.hbase.client.RpcRetryingCaller] - Call exception, tries=10, retries=35, started=38401 ms ago, cancelled=false, msg= 2017-11-21 17:46:04,998 INFO [org.apache.hadoop.hbase.client.RpcRetryingCaller] - Call exception, tries=11, retries=35, started=48413 ms ago, cancelled=false, msg=
Exception in thread "main" java.io.IOException: java.lang.reflect.InvocationTargetException at org.apache.hadoop.hbase.client.ConnectionFactory.createConnection(ConnectionFactory.java:240) at org.apache.hadoop.hbase.client.ConnectionFactory.createConnection(ConnectionFactory.java:218) at org.apache.hadoop.hbase.client.ConnectionFactory.createConnection(ConnectionFactory.java:119) at HBaseAuth.main(HBaseAuth.java:33) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144) Caused by: java.lang.reflect.InvocationTargetException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:422) at org.apache.hadoop.hbase.client.ConnectionFactory.createConnection(ConnectionFactory.java:238) ... 8 more Caused by: java.lang.UnsupportedOperationException: Unable to find org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory at org.apache.hadoop.hbase.util.ReflectionUtils.instantiateWithCustomCtor(ReflectionUtils.java:36) at org.apache.hadoop.hbase.ipc.RpcControllerFactory.instantiate(RpcControllerFactory.java:58) at org.apache.hadoop.hbase.client.ConnectionManager$HConnectionImplementation.createAsyncProcess(ConnectionManager.java:2256) at org.apache.hadoop.hbase.client.ConnectionManager$HConnectionImplementation.<init>(ConnectionManager.java:691) at org.apache.hadoop.hbase.client.ConnectionManager$HConnectionImplementation.<init>(ConnectionManager.java:631) ... 13 more Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:264) at org.apache.hadoop.hbase.util.ReflectionUtils.instantiateWithCustomCtor(ReflectionUtils.java:32) ... 17 more
Exception in thread "main" org.apache.hadoop.security.AccessControlException: SIMPLE authentication is not enabled. Available:[TOKEN, KERBEROS] at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:422) at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:106) at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:73) at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:2110) at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1305) at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1301) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1317) at org.apache.hadoop.fs.Globber.getFileStatus(Globber.java:57) at org.apache.hadoop.fs.Globber.glob(Globber.java:252) at org.apache.hadoop.fs.FileSystem.globStatus(FileSystem.java:1674) at org.apache.hadoop.mapred.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:259) at org.apache.hadoop.mapred.FileInputFormat.listStatus(FileInputFormat.java:229) at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:315) at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:200) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:248) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:246) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.rdd.RDD.partitions(RDD.scala:246) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:248) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:246) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.rdd.RDD.partitions(RDD.scala:246) at org.apache.spark.SparkContext.runJob(SparkContext.scala:1911) at org.apache.spark.rdd.RDD$$anonfun$foreach$1.apply(RDD.scala:875) at org.apache.spark.rdd.RDD$$anonfun$foreach$1.apply(RDD.scala:873) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) at org.apache.spark.rdd.RDD.withScope(RDD.scala:358) at org.apache.spark.rdd.RDD.foreach(RDD.scala:873) at HDFS.SparkHDFS$.main(SparkHDFS.scala:43) at HDFS.SparkHDFS.main(SparkHDFS.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144) Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): SIMPLE authentication is not enabled. Available:[TOKEN, KERBEROS] at org.apache.hadoop.ipc.Client.call(Client.java:1475) at org.apache.hadoop.ipc.Client.call(Client.java:1412) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229) at com.sun.proxy.$Proxy20.getFileInfo(Unknown Source) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:771) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102) at com.sun.proxy.$Proxy21.getFileInfo(Unknown Source) at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:2108) ... 34 more
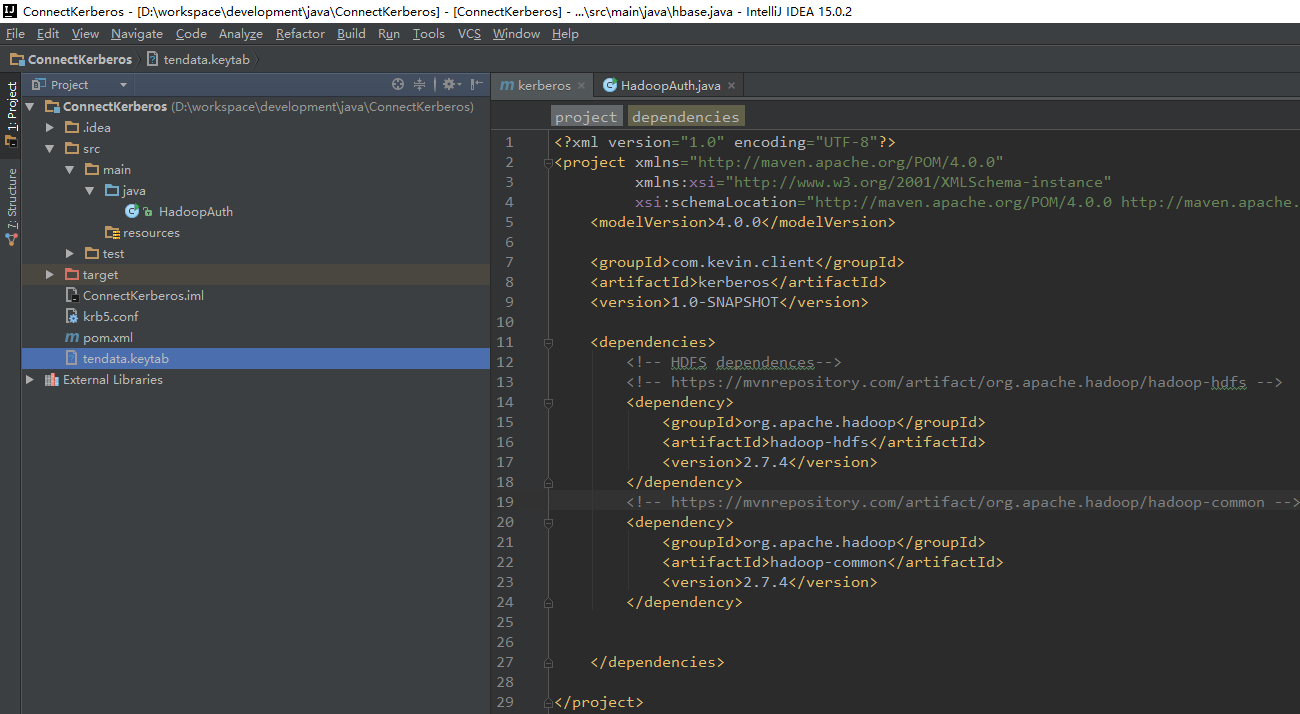
直接在 Resource 目录下加入 core-site.xml 配置文件即可。
当人加入了上述配置文件后,重新运行又会出现下面的错误
6. Can’t get Master Kerberos principal for use as renewer
Exception in thread "main" java.io.IOException: Can't get Master Kerberos principal for use as renewer at org.apache.hadoop.mapreduce.security.TokenCache.obtainTokensForNamenodesInternal(TokenCache.java:116) at org.apache.hadoop.mapreduce.security.TokenCache.obtainTokensForNamenodesInternal(TokenCache.java:100) at org.apache.hadoop.mapreduce.security.TokenCache.obtainTokensForNamenodes(TokenCache.java:80) at org.apache.hadoop.mapred.FileInputFormat.listStatus(FileInputFormat.java:205) at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:313) at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:202) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.rdd.RDD.partitions(RDD.scala:237) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.rdd.RDD.partitions(RDD.scala:237) at org.apache.spark.SparkContext.runJob(SparkContext.scala:1929) at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:927) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111) at org.apache.spark.rdd.RDD.withScope(RDD.scala:316) at org.apache.spark.rdd.RDD.collect(RDD.scala:926) at org.apache.spark.api.java.JavaRDDLike$class.collect(JavaRDDLike.scala:339) at org.apache.spark.api.java.AbstractJavaRDDLike.collect(JavaRDDLike.scala:46) at SparkAuth.main(SparkAuth.java:43) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
java.lang.Exception: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: error in shuffle in localfetcher#1 at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:492) at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:559) Caused by: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: error in shuffle in localfetcher#1 at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:134) at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:377) at org.apache.hadoop.mapred.LocalJobRunner$Job$ReduceTaskRunnable.run(LocalJobRunner.java:347) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.lang.ExceptionInInitializerError at org.apache.hadoop.mapred.SpillRecord.<init>(SpillRecord.java:71) at org.apache.hadoop.mapred.SpillRecord.<init>(SpillRecord.java:62) at org.apache.hadoop.mapred.SpillRecord.<init>(SpillRecord.java:57) at org.apache.hadoop.mapreduce.task.reduce.LocalFetcher.copyMapOutput(LocalFetcher.java:125) at org.apache.hadoop.mapreduce.task.reduce.LocalFetcher.doCopy(LocalFetcher.java:103) at org.apache.hadoop.mapreduce.task.reduce.LocalFetcher.run(LocalFetcher.java:86) Caused by: java.lang.RuntimeException: Secure IO is not possible without native code extensions. at org.apache.hadoop.io.SecureIOUtils.<clinit>(SecureIOUtils.java:71) ... 6 more 2020-04-1720:16
这个问题是由于没有使用 Tative library 导致的,在程序运行第一行一般会有个警告 Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
这是没有加载动态库。一般情况下 Hadoop 的二进制报已经包含了,只是没有在系统中加载。
出现这个问题是在集群客户端使用 yarn jar demo.jar 在集群中运行 mapreduce 任务的时候报错了。
1 2 3 4 5 6 7 8 9 10 11 12 13
Error: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: error in shuffle in fetcher#30 at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:134) at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:377) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:174) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:168) Caused by: java.io.IOException: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out. at org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl.checkReducerHealth(ShuffleSchedulerImpl.java:396) at org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl.copyFailed(ShuffleSchedulerImpl.java:311) at org.apache.hadoop.mapreduce.task.reduce.Fetcher.copyFromHost(Fetcher.java:361) at org.apache.hadoop.mapreduce.task.reduce.Fetcher.run(Fetcher.java:198)